Można już korzystać z PLLuM – polskiego modelu AI. „To inwestycja w cyfrowe państwo”

Ministerstwo Cyfryzacji przeznaczyło dotąd na projekt 14,5 mln złotych, a w nieodległej przyszłości zwiększy tę kwotę.
Chcę złożyć wniosek o pozwolenie na budowę studni. Ile zapłacę? Jak uzyskać dofinansowanie pobytu dziecka w żłobku? Ile dni urlopu powinienem mieć w ciągu roku? Jakie warunki należy spełnić, aby zostać żołnierzem zawodowym, nie będąc wcześniej żołnierzem rezerwy? To niektóre sugestie pytań, które można zadać nowemu polskiemu modelowi językowemu PLLuM. Ich ukierunkowanie tematyczne nie powinno dziwić. Jednym z głównych zadań narzędzia jest unowocześnienie sektora publicznego. Ma współdziałać z wirtualnym asystentem w mObywatelu, wesprzeć pracę urzędników oraz pomagać nauczycielom w układaniu angażujących lekcji.
– Tworzymy fundament pod inteligentne usługi publiczne i innowacje, które będą realnym wsparciem zarówno dla administracji, jak i biznesu – przekonywał podczas wczorajszej konferencji prasowej Krzysztof Gawkowski, wicepremier i minister cyfryzacji.
PLLuM już działa, ale to dopiero początek
Po roku intensywnych prac i testów PLLuM został udostępniony użytkownikom. Na ten moment jego stworzenie pochłonęło 14,5 mln złotych, które pochodziło z budżetu Ministerstwa Cyfryzacji. Kolejne 19 mln pójdzie na wdrożenie modelu do usług, z których na co dzień korzystają Polacy. W realizacji tego celu istotną rolę odegrają Centralny Ośrodek Informatyki i Akademickie Centrum Komputerowe CYFRONET AGH. Druga z instytucji dostarczy mocy obliczeniowych do dalszego szkolenia modeli.
Scrolling spod znaku Wikipedii. Dlaczego warto zwrócić uwagę na WikiTok?
Skala nie powala
Czym rodzimy model ma od rozwiązań pokroju ChatuGPT, Gemini czy Copilota? Raczej nie skalą i zaawansowaniem. Polska propozycja wykorzystuje od 8 do 70 miliardów parametrów sieci neuronowych, podczas gdy GPT4 – ponad trzy razy więcej. Im większa liczba, tym szybsze i precyzyjniejsze odpowiedzi chatbota. O tym, że w takim zderzeniu z amerykańskimi czy chińskimi gigantami technologicznymi będziemy wypadać gorzej, w rozmowie z Jakubem Dymkiem opowiadała ekspertka Amba Kak.
– Nie sądzę, że dziś państwa narodowe są w stanie poświęcić środki wystarczające do tego, aby zbudować od podstaw własny model, który choćby w połowie był w stanie konkurować z tymi istniejącymi na rynku. W związku z tym rzucają jakimiś drobnymi w kierunku problemu pod tytułem AI i liczą, że slogan o wielkich publicznych inwestycjach się przyjmie – tłumaczyła specjalistka.
Narzędzie o eksperckich fundamentach
W projektach takich jak PLLuM bardziej liczy się dlatego celowość. Jak wspomnieliśmy wcześniej, model ma przede wszystkim stymulować wprowadzanie sektora publicznego w erę cyfrową. Właśnie dlatego został dostosowany do specyfiki języka polskiego i terminologii administracji publicznej. Poza tym jest trenowany na ręcznie opracowywanych danych organicznych. Komendy zwane promptami oraz sugerowane odpowiedzi układał zespół złożony z ponad 50 specjalistów. Wśród nich znaleźli się eksperci z Uniwersytetu Łódzkiego, Naukowej i Akademickiej Sieci Komputerowej oraz Instytutu Slawistyki PAN.

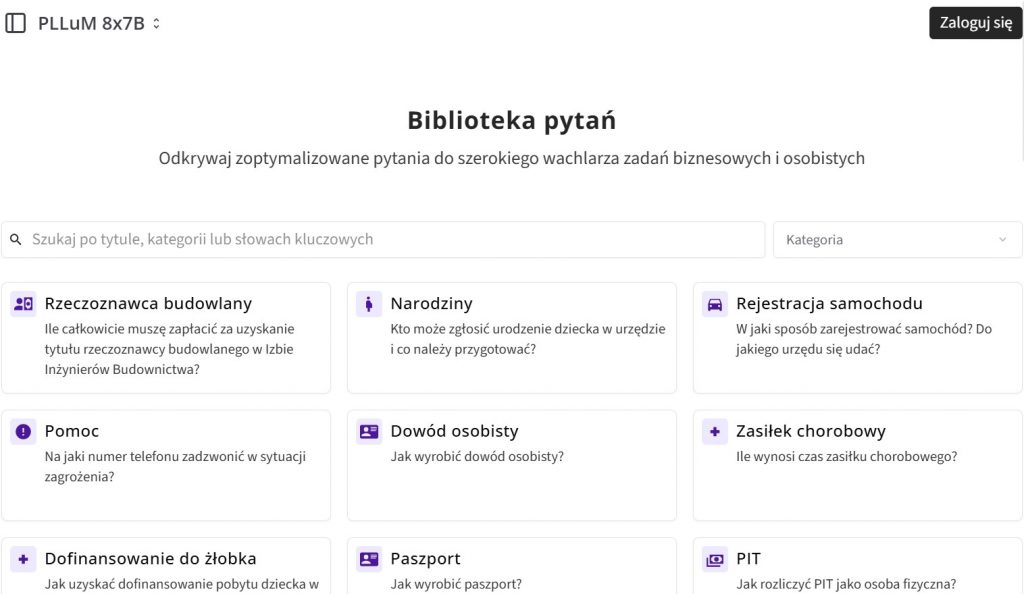
Z zaproszeniem do projektu ekspertów czuwających nad danymi wiąże się jeszcze jeden atut. Twórcom dużych modeli językowych często zarzuca się nieuprawnioną eksploatację różnych źródeł tekstowych. Ministerstwo Cyfryzacji chce za to dawać dobry przykład i etycznie pozyskiwać zasoby treningowe.
PLLuM, który możecie bezpłatnie przetestować TU, to nie pierwszy rodzimy LLM. Społeczność SpeakLeash we współpracy z krakowską Akademią Górniczo-Hutniczą zaprezentowała w ubiegłym roku Bielika. Jak przyznaje jego pomysłodawca, Sebastian Kondracki, model dobrze sprawdzi się w pracy nad gotowym już tekstem. Nieco gorzej pójdzie mu wyszukiwanie wiedzy.

{kind=link}